What does a model see?
Training with no labels. How a vision model learns to organize the world without being told what anything is.
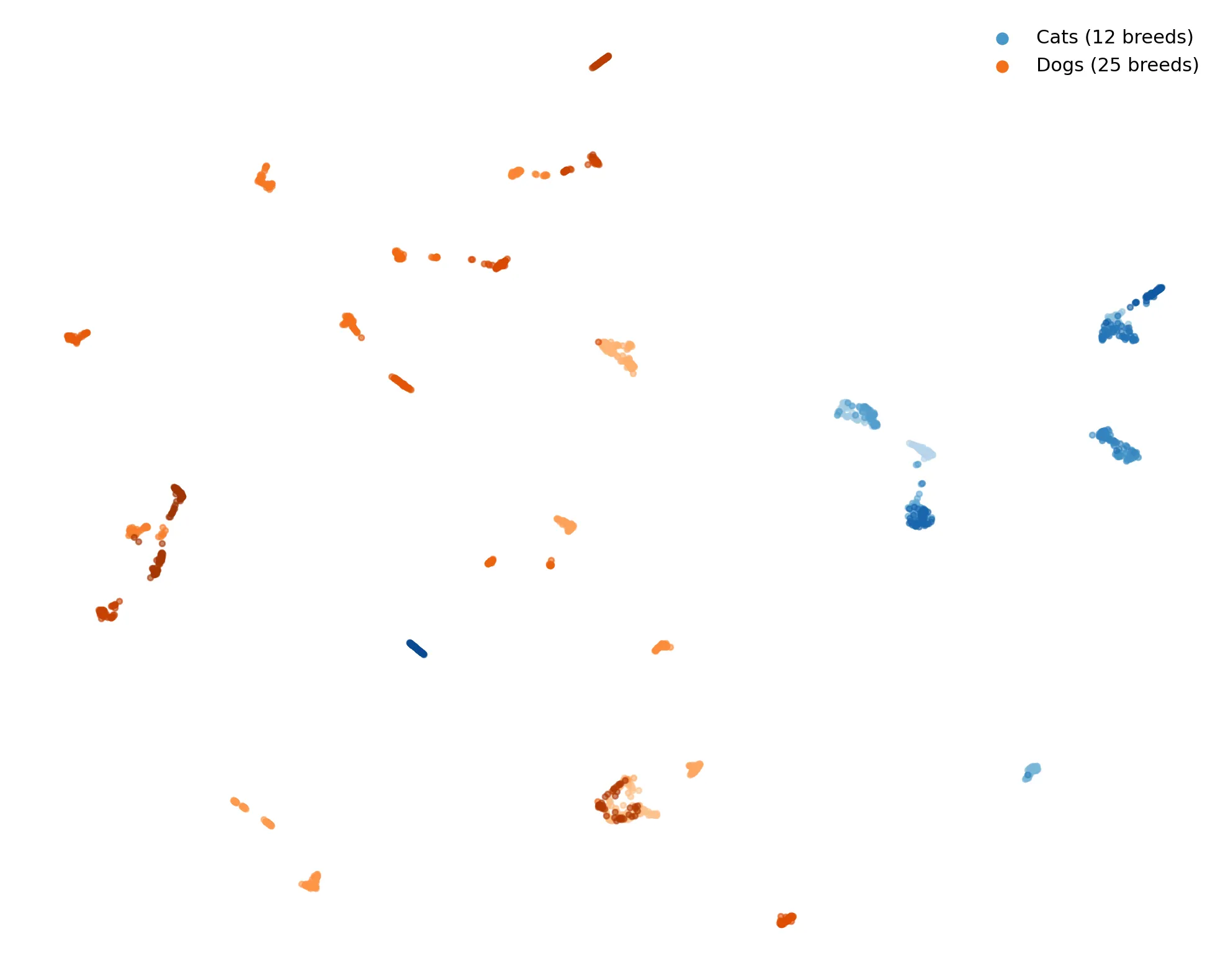
This is DINOv2, a self-supervised vision transformer. It learned from images alone. No “this is a beagle”, nor “this is a cat”. Yet when you project its representations to 2D, breeds cluster. Cats on one side, dogs on the other. The model is trained on a dataset with 142 million images. The latest model DINOv3 was trained with an order of magnitude larger dataset, where the initial pool of images were 17B, and reduced to 1 689 million images.

The model splits this image into 1369 patches. Each one becomes a 768-dimensional vector. Project them all to 2D, color by ground truth segmentation:

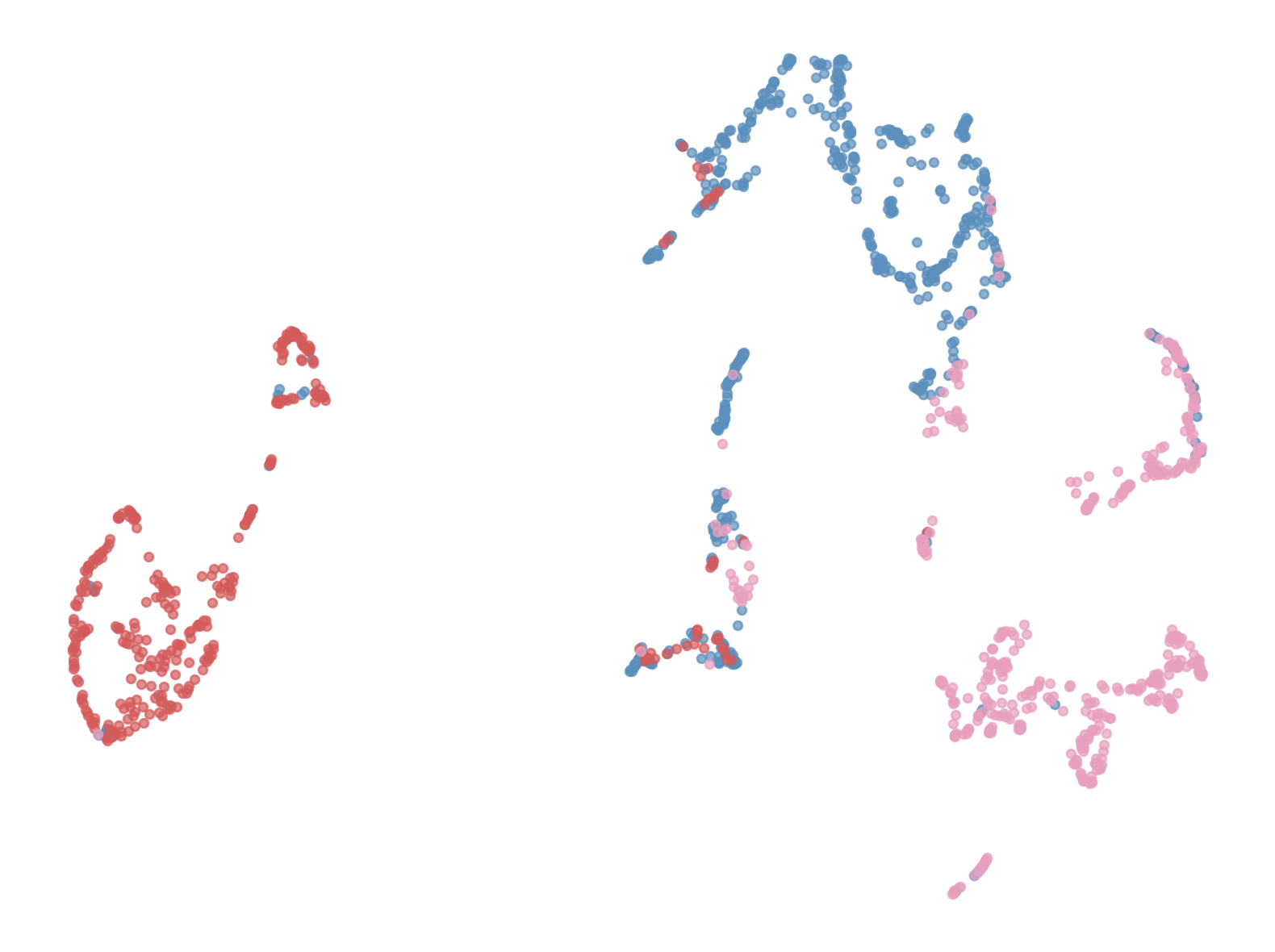
Same colors, same clusters. The model was never trained on segmentation. It has no concept of horse or person.
Yet its internal representations capture the semantic structure of the image. Objects separate. Boundaries emerge. All without direction.
These representations let you do things the model was never trained for. Classify. Search. Cluster. Compare.
What I find interesting is that none of this required defining what to look for. The structure comes from the data itself.